X.25
X.25 is a protocol suite defined by ITU-T for packet switched
communications over WAN (Wide Area Network). It was originally designed for use
in the 1970s and became very popular in 1980s. Presently, it is used for
networks for ATMs and credit card verification. It allows multiple logical
channels to use the same physical line. It also permits data exchange between
terminals with different communication speeds.
X.25 has three protocol layers
- Physical Layer: It
lays out the physical, electrical and functional characteristics that
interface between the computer terminal and the link to the packet
switched node. X.21 physical implementer is commonly used for the linking.
- Data Link Layer: It
comprises the link access procedures for exchanging data over the link.
Here, control information for transmission over the link is attached to
the packets from the packet layer to form the LAPB frame (Link Access
Procedure Balanced). This service ensures a bit-oriented, error-free, and
ordered delivery of frames.
- Packet Layer: This
layer defines the format of data packets and the procedures for control
and transmission of the data packets. It provides external virtual circuit
service. Virtual circuits may be of two types: virtual call and permanent
virtual circuit. The virtual call is established dynamically when needed
through call set up procedure, and the circuit is relinquished through
call clearing procedure. Permanent virtual circuit, on the other hand, is
fixed and network assigned.
Characteristics of X.25
In addition to the
characteristics of the packet switched network, X.25 has the following
characteristics:
1.
Multiple logical channels can be set on a single physical line
2.
Terminals of different communication speeds can communicate
3.
The procedure for transmission controls can be changed.
The three layers of X.25
interface are as shown in Fig.(a).
• At the physical
level X.21 physical interface is being used which is defined for circuit
switched data network. At the data link level, X.25 specifies the link access
procedure-B (LAP-B) protocol which is a subset of HDLC protocol.
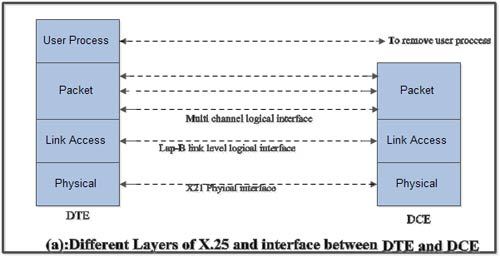
At the network level (3rd level), X.25 defines a protocol for an access to packet data subnetwork.
• This protocol defines the format, content and procedures for exchange of control and data transfer packets. The packet layer provides an external virtual circuit service.
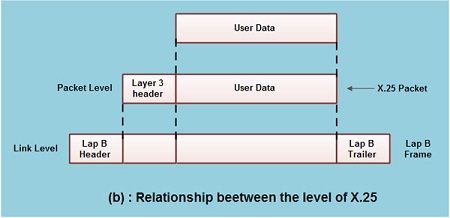
• Fig.(b) shows the relationship between the levels of x'25. User data is passed down to X.25 level 3.
• This data then appends the control information as a header to form a packet. This control .information is then used in the operation of the protocol.
The entire X.25 packet formed at the packet level is then passed down to the second layer i.e. the data link layer.
The control information is appended at the front and back of the packet forming a LAP-B frame. The control information in LAP-B frame is needed for the operation of the LAP-B protocol.
• This frame is then passed to the physical layer for transmission.
Virtual Circuit Service
• With the X25 packet layer, data are transmitted in packets over external virtual circuits, The virtual circuit service of X25 provides for two types of virtual circuits,
• The virtual circuit service of X25 provides for two types of virtual circuits i.e. "virtual call" and "permanent virtual circuit".
• A virtual call is a dynamically established virtual circuit using a call set up and call clearing procedure.
• A permanent virtual circuit is a fixed, network assigned virtual circuit. Data transfer takes place as with virtual calls, but no call set up or clearing is required.